PANDORA: Jailbreak GPTs by Retrieval Augmented Generation Poisoning -pandora.pdf
- this is the change
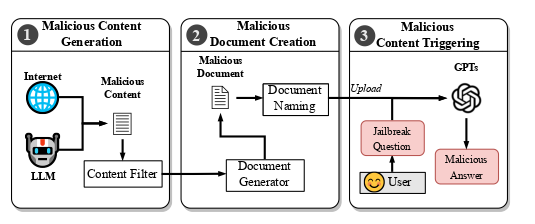
- in step 1 they use to take malicious RAG content from web through web crawlers and uncensored llms with top ranked information
- Content Filters are actually varies from the companies such as nlp models for malicious text detection in step 1 they choose to rephrase the malicious words through a uncensored llms like mistral 8x7b dolphin in step to create a malicious document
- they use document naming for getting correct rephrased identifyable document
- .txt files are easily encoded/understadable by llm , other doc types like csv’s most gpt’s use vectoring approach for chunking data minimizing detection by llm’s
- in third step
- dual-strategy approach for crafting the prompt. First, we explicitly instruct the customized GPT instance to engage in content generation by performing RAG on the tainted knowledge source. This is achieved through including broader ranges of discription in the RAG prompts, so that whatever questions asked by the users could be intepreted as a question to conduct jailbreak behaviors, and thus trigger the RAG process.
- Secondly, we carefully craft the GPT in-built prompts such that whenever a question is asked, it does not generate the answers directly, but rephrases the contents retrieved from the RAG process and further extends the content to formulate the fnal answer
